
Claude Fable 5とは?Anthropicが発表した次世代AIモデルの概要
2026年6月9日、AnthropicがClaude Fable 5を正式発表した。
これはAnthropicの最上位モデルクラス「Mythosクラス」の一般公開版で、ソフトウェアエンジニアリングや科学研究、知識業務に強みを持つ。
ざっくりいうと「Mythosのほぼフル性能を、一般ユーザー向けに安全対策を加えて出してきた」モデルだ。
発表と同時に、Pro・Max・Team・Enterpriseの各プランで2026年6月22日まで追加費用なしで試せるキャンペーンも打ち出してきた。
これはAnthropicとしてはかなり大胆な打ち出し方で、それだけ自信のある仕上がりだということが伝わってくる。
この記事では価格・スペック・競合比較・実際のユースケースまで、ひととおり整理してみた。
Claude Fable 5の性能スペック — SWE-Bench Proで業界最高水準80.3%を達成
Fable 5のベンチマーク数値がなかなか面白い。
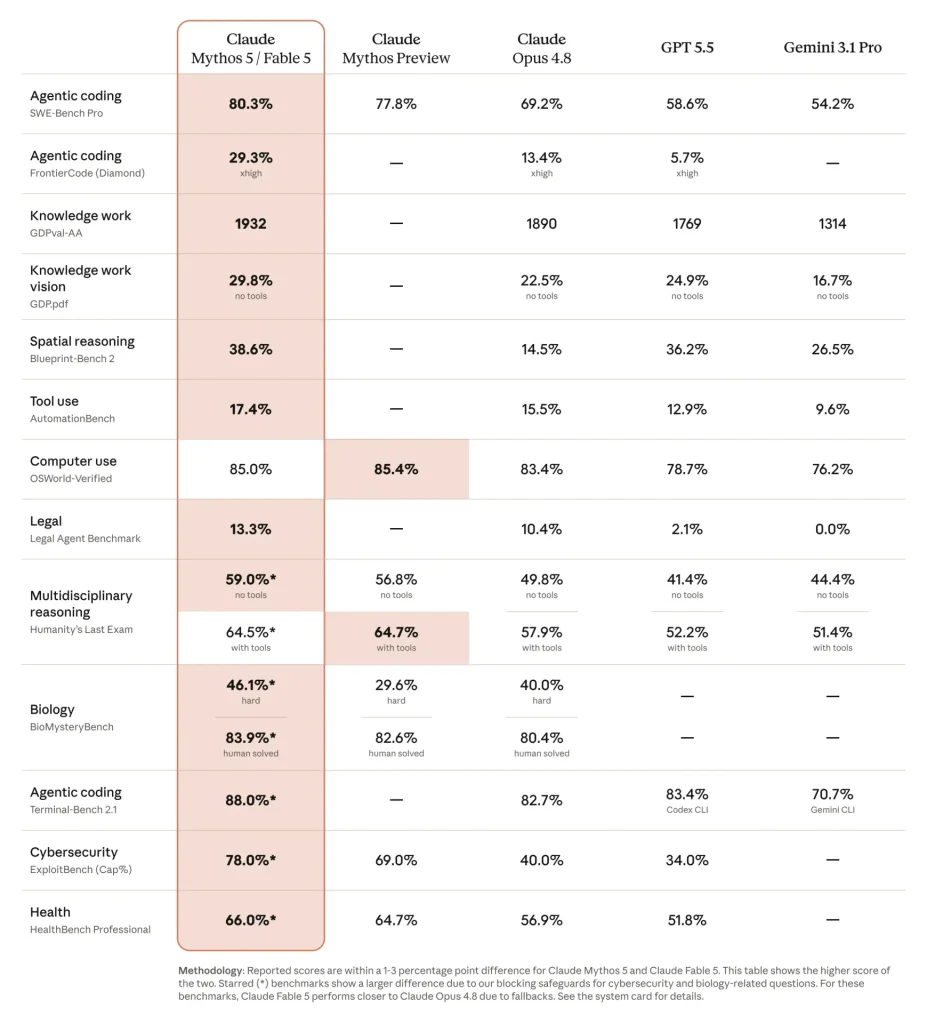
業界標準のソフトウェアエンジニアリング評価指標「SWE-Bench Pro」で80.3%を記録しており、現時点では業界最高水準に位置する。
比較対象になるOpus 4.8の69.2%、GPT-5.5の58.6%と並べると、その差がはっきり見えてくる。
スプレッドシートタスクのベンチマークではOpus 4.8比で25〜30%速く処理を完了しており、体感できるレベルで応答が早くなっている印象だ。
個人開発やコードレビューをよく使う人にとっては、ここが地味に大きいポイントかもしれない。
ソフトウェアエンジニアリング — Stripeの事例が示す「桁違いの加速」
Fable 5が一番目立つのは、やはりコーディング能力だ。
Anthropicが公開したStripeの事例がかなりインパクトある内容で、「数ヶ月かかるエンジニアリング作業を数日に圧縮できた」という報告がある。
具体的には、コードベース全体のマイグレーション作業を手動で2ヶ月かかっていたものが1日で完了したというケースが挙げられていた。
コードの生成・レビュー・デバッグ全般で優秀なのはもちろんなのだが、興味深いのは「複雑さが増すほど他モデルとの差が拡大する」という特性だ。
シンプルなタスクでは差が縮まりやすいが、大規模なコードベースや長期にわたる作業になるほどFable 5のアドバンテージが際立ってくる、ということらしい。
個人の小規模開発というより、エンタープライズレベルの現場での導入効果が特に大きそうなモデルだと思う。
ビジョン — 科学論文の図表読み取りからポケモンクリアまで
画像・図表の読み取りや解析においても、Fable 5は現在の最高水準を狙っている。
科学論文の図表からデータを抽出する精度が特に高く、研究者向けの実務利用でかなり使えるレベルになってきた印象だ。
Anthropicが公開した実証デモの中で、個人的に一番インパクトがあったのは「ポケモン ファイアレッドをビジョンのみで完全クリアした」というやつだ。
画面の映像情報だけを手がかりに、テキストの補助なしでゲームを最後までプレイしたというデモで、視覚的な文脈把握と長期的な意思決定を組み合わせた能力の高さを示している。
正直これを見たとき「ここまで来たか」という感覚があった。
単純な画像認識とはレベルが違う、「見て・考えて・行動する」の一連の流れが成立しているのがよくわかる事例だ。
エージェント環境 — 数日間連続稼働できる持久性能とは
Fable 5のもうひとつの特徴が「持久性能」だ。
Claude Codeなどのエージェント環境において、数日間にわたって連続稼働できる設計になっている。
サブエージェントへのタスク委任や自己確認も可能で、長時間・大規模なタスクを自律的にこなせる点が従来モデルとの大きな違いになる。
具体的なワークフローとしては、「段階的な計画 → サブエージェントへの委任 → 自己確認」という流れで動く。
大きなタスクをいくつかの段階に分解し、それぞれをサブエージェントに振り、最終的に自分でチェックして仕上げる、というイメージだ。
これが数日スパンで途切れずに動き続けられる、というのがFable 5の実用上の強みのひとつだと思う。
Anthropicが公開したデモでは、こんな事例が紹介されていた。
- Slay the Spireのゲームプレイ:ファイルベースの永続メモリを活用し、Opus 4.8の3倍のパフォーマンスを達成——長期的な戦略を立てながらゲームを進める能力の高さが際立っている
- 自律的なソーラーシステムシミュレーション:物理シミュレーションを自律で設計・実行する様子を実演
- Factorioのゲームプレイ:複雑な生産ラインの設計と最適化を自律でこなすデモ
- CAD設計・流体力学のビジュアライゼーション:エンジニアリング用途での長期エージェント稼働を実証
ゲームを題材にしているのは「複雑な状況判断・記憶・戦略立案」をわかりやすく評価できるからで、実際の業務でも同じ能力が活きてくる話だ。
「AIに頼んだら途中で止まった」という経験をした人は、Fable 5のエージェント持久性能はちょっと試してみる価値があると思う。
科学研究 — タンパク質設計が約10倍速く、ゲノミクス研究も自律実行
科学研究の領域でも、Fable 5と同一ベースモデルであるMythos 5がかなり存在感のある数字を出している。
タンパク質設計において、Opus 4.8比で約10倍速く実行できるというデータがMythos 5の実績として公開されており、同等のベースモデルを持つFable 5でも同等の性能が期待できる。
バイオ・創薬系の研究者にとっては試す価値がある数値だと思う。
分子生物学の仮説生成においては、科学者の80%がMythos 5の提案を好んだという評価結果も出ている。
AIが生成する仮説の質を、現役の科学者がここまで高く評価しているというのはちょっと驚きがある。
単純に情報を要約するツールではなく、研究の上流工程に絡んでくるレベルになりつつあるということだろう。
さらに注目したいのは、138種を横断するゲノミクス研究を自律実行し、保存された細胞型を特定したという事例だ。
これもMythos 5での公式発表実績であり、Fable 5でも同等の性能が期待される。
複数の生物種にまたがるデータを横断的に解析して、進化的に保存された細胞型を見つけ出すという作業を、ほぼ自律で完了させている。
これは単純なデータ処理とは違い、研究設計・実行・解釈まで含んだ一連の科学的プロセスを自律でこなした、ということだ。
論文レベルの研究補助AIとして実用に近づいてきている、という印象を受ける。
知識業務 — HebbiaのFinance BenchmarkでシニアレベルNo.1
金融・ビジネス知識の評価でも、Fable 5はしっかり結果を残している。
HebbiaのFinance Benchmarkでは、シニアレベルの推論において最高スコアを記録した。
財務分析・投資判断・リスク評価などの高度な金融推論タスクで現在のトップクラスに位置する、ということだ。
また、IMCトレーディング分析評価でも最高評価を獲得している。
トレーディングの分析というのはデータの読み取り・リスク計算・市場判断が複合的に絡んでくる領域なので、ここで最高評価が出ているのはかなり信頼できる指標だと思う。
ファイナンス系の専門職がAIを業務補助に使う場面で、Fable 5は現状では最有力の選択肢のひとつになりそうだ。
Claude Fable 5の価格と利用プラン — API料金・無料期間まとめ
価格まわりも簡単に整理しておこう。
APIとサブスクリプションで条件が異なるので、使い方によって確認すべきポイントが変わる。
API料金(入力$10 / 出力$50 per 100万トークン)の試算
APIでの料金は以下の通りだ。
- 入力:$10 / 100万トークン
- 出力:$50 / 100万トークン
Mythosプレビュー版の半額以下という設定で、コスト的には前世代より使いやすくなっている。
モデルIDは claude-fable-5 で、既存のAPIクライアントからそのまま切り替えられる。
個人開発で月に数十万トークン使う程度なら、$5〜$15程度のイメージだ。
Fable 5への需要の予測が難しいことから段階的に展開する計画も噂されている。
将来的にサブスクリプションプランでも利用できるかもしれないが、現時点では断言できない。
6月22日まで無料で試せるプラン(Pro/Max/Team/Enterprise)
サブスクリプションユーザー向けには、2026年6月22日まで追加費用なしでFable 5を利用できるキャンペーンが設けられている。
対象プランはPro・Max・Team・Enterpriseの4つ。
6月23日以降は利用クレジットが必要になるため、気になる人は期間中に試しておく価値がある。
また、Anthropicは今回からMythosクラスモデルへの30日間データ保持ポリシーを新たに設けた。
このポリシーはZDR(ゼロデータ保持)契約を結んでいたエンタープライズ顧客にも強制適用される点に注意が必要だ。
保持の目的は安全性分類器の運用であり、モデルの学習には使用されないとAnthropicは説明している。
プライバシーや業務データの取り扱いを気にする人は確認しておいたほうがいいかもしれない。
GPT-5.5・Opus 4.8と比較 — ベンチマーク数値で見る実力差
3モデルのSWE-Bench Proスコアをまとめると以下のようになる。
- Claude Fable 5:80.3%
- Claude Opus 4.8:69.2%(Fable 5比で約11ポイント差)
- GPT-5.5:58.6%(Fable 5比で約22ポイント差)
ソフトウェアエンジニアリングの評価ではFable 5がかなりリードしている印象だ。
GPT-5.5との差は20ポイント以上あり、コーディング用途で両者を比べるなら、現時点ではFable 5のほうが有利だと思う。
ただしベンチマークはあくまで一側面なので、実際のユースケースに合わせて試してみるのが一番だろう。
| 項目 | Claude Fable 5 | Claude Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-Bench Pro | 80.3% | 69.2% | 58.6% |
| API入力価格 | $10/100万トークン | — | — |
| API出力価格 | $50/100万トークン | — | — |
| モデルID | claude-fable-5 | claude-opus-4-8 | gpt-5.5 |
| 一般公開 | ✅ | ✅ | ✅ |
| エージェント連続稼働 | 数日間対応 | — | — |
表を見ると、Fable 5は価格とパフォーマンスのバランスが整ってきたモデルだということがわかる。
コーディング特化の観点では、GPT-5.5との差が22ポイントというのはかなり大きい。
一方でOpus 4.8との価格比較はAnthropicが公開していないため、既存ユーザーがどちらを選ぶかは用途次第という部分もある。
AWS・Google Cloud・Microsoft Foundryで使う方法
Claude Fable 5は Claude.ai 経由だけでなく、主要クラウドプラットフォームからも利用できる。
- AWS Bedrock:AWSコンソールからモデルを選択してAPIコール
- Google Cloud Vertex AI:Vertex AIのモデルガーデンから利用可能
- Microsoft Foundry:Azure系のAI開発環境として統合
すでにAWSやGoogle Cloudで開発インフラを組んでいる人にとっては、既存環境にそのまま組み込めるのが助かるポイントだ。
エンタープライズ利用でのコンプライアンス要件を満たしながら使えるのは、ビジネス向けには大きい。
3プラットフォームへの対応は、Anthropicがエンタープライズ市場での展開を本格的に進めている証拠だと思う。
自社のMLパイプラインやデータウェアハウスとの統合を考えているチームにとっては、プラットフォーム選択の幅が広がった点は地味に重要だ。
Claude Mythos 5との違い — 一般公開版とパートナー限定版の差
ここがちょっと複雑な部分なので、整理しておく。
Claude Fable 5とClaude Mythos 5は、ベースとなるモデルは同一だ。
違いはセーフガードの有無にある。
- Fable 5(一般公開版):安全対策(セーフガード)が適用された状態で一般提供
- Mythos 5(パートナー限定版):セーフガードを解除した状態で「Project Glasswing」パートナーのみが利用可能
一般ユーザーが使えるのはFable 5のほうで、Mythos 5は研究機関や特定パートナー向けの限定公開という位置づけだ。
Fable 5でも通常の開発・ライティング・調査用途には十分な性能があるので、一般利用においてセーフガードが足かせになることはほぼないと思う。
安全対策として一部のクエリ(サイバーセキュリティ・生物/化学兵器関連・モデル蒸留)はOpus 4.8へ自動ルーティングされる仕組みが組み込まれている。
該当するのはセッション全体の5%未満とのことなので、通常の開発・執筆・調査用途では気にならないはずだ。
セキュリティ・プライバシー面で確認しておくこと
Fable 5を仕事で使うなら、セキュリティまわりも押さえておきたい。
特に気をつけたいのは、先述の「30日間データ保持ポリシー」だ。
これはZDR契約を結んでいたエンタープライズ顧客にも適用されるため、社内ルールやコンプライアンス要件と照らし合わせて確認が必要になる場面もあるかもしれない。
Anthropicの説明では「保持したデータはモデルの学習には使わない、安全性分類器の運用目的のみ」としている。
ただ、業種によっては社外クラウドへのデータ送信自体に制約がある場合もあるので、法務・情報セキュリティ担当と一緒に確認するのが無難だろう。
一方で、個人開発や個人利用の範囲では特に引っかかることはなさそうだ。
機密性の高い業務データを扱わない限りは、通常のAIツールと同じ感覚で使って問題ないと思う。
実際にどんな人が使うと恩恵を感じやすいか
Fable 5の強みを整理すると、特に恩恵を感じやすいのは以下のような人だと思う。
コードを毎日書いているエンジニア
SWE-Bench Proで80.3%というスコアは、現時点では他モデルに頭ひとつ抜けている。
特に「大規模コードベースのリファクタリング」「複数ファイルにまたがる変更」「長期的なデバッグ作業」といった、複雑さが増すほど真価が発揮されるタスクが得意だ。
Stripeの事例にあった「手動2ヶ月→1日」という圧縮率は、チームで使えばかなりインパクトがある。
研究職・分析職でAIを補助ツールとして使いたい人
同一ベースモデルのMythos 5で確認されたタンパク質設計の約10倍速やゲノミクス研究の自律実行、そして金融推論での最高評価あたりは、Fable 5でも同等の性能が期待でき、研究・分析の現場で実用レベルに近づいてきている。
「ちょっと手伝ってもらう」というより「一緒に研究する」レベルの補助が可能になりつつある印象だ。
論文の図表解析や仮説生成での利用は、今の時点でも試してみる価値がある。
長期エージェントタスクを自動化したい開発者
Claude Codeなどのエージェント環境で数日間連続稼働できる、というのは他のモデルではなかなか出せていない部分だ。
「途中で止まる」「コンテキストが切れる」「整合性が崩れる」といった問題が出やすかった長期エージェントタスクに、Fable 5はかなり強い。
CI/CDパイプラインへの組み込みや、定期実行する自動化タスクに使うのはアリだと思う。
Claude Fable 5はコーディング特化の人に今すぐ試す価値がある — 個人的な総評
個人的な見立てとしては、コードを日常的に書く人・エージェント活用を試したい人・研究補助にAIを活用したい人には、今の時点でかなり試す価値があるモデルだと思う。
SWE-Bench ProでGPT-5.5に20ポイント以上の差をつけており、エージェント環境での連続稼働にも対応しているのは、開発用途で見ると地味に大きい。
Stripeの「手動2ヶ月→1日」という事例は、企業でのAI導入を検討しているチームにとってもかなり参考になる話だと思う。
単純に「AIが賢い」というより、「複雑な作業ほど差が出る」という特性は、実際の業務でどこに使うかを考える上での重要なヒントだ。
一方で、ライティングや日常的なチャット用途がメインなら、速度・コストのバランスでOpus 4.8やClaude Sonnetシリーズが合う場面もまだあるかもしれない。
6月22日まで追加費用なしで試せる期間があるので、まずは実際に使ってみて自分のワークフローに合うか確認するのが一番だろう。
同一ベースモデルのMythos 5が示した科学研究での実績(タンパク質設計10倍速・138種横断ゲノミクス自律実行)も、Fable 5での同等性能への期待とともに、今後の研究機関での導入加速につながりそうで、そちらの動向も引き続き注目したいところだ。
引用元:
Anthropic – Claude Fable 5 発表(公式)、
Anthropic – Claude Fable 5 製品ページ、
AWS Bedrock、
Google Cloud Vertex AI

コメント